HA and DR in a cloud environment such as Amazon EC2
By: William Alexander in Cloud Tutorials on 2012-10-20
When you have decided to move your application hosting to the cloud such as amazon ec2 instances, the common question is how can High Availability and Disaster Recovery can be achieved in a cloud environment.
This tutorial describes the best practice and a system architecture that you can use in your cloud deployment when you want to use HA and DR.
The proposed System Architecture is designed based on two Virtualized cloud environments, one for the Production site and the other for the Disaster Recovery site. The production site and the DR site can be in two different cloud environments. For example you can host the production site in amazon ec2 and the DR site in Windows Azure platform or any other IAAS provider in your local country.
As any application usually has a database, the Database server will be replicated in a "Master-Slave" architecture and the snapshots of the volumes will be taken at periodic intervals and saved to the Cloud Storage as backup.
A similar DB slave will be replicated in the DR site using the VPN Manager and backed up to the DR Site which is hosted externally in a different cloud infrastructure.
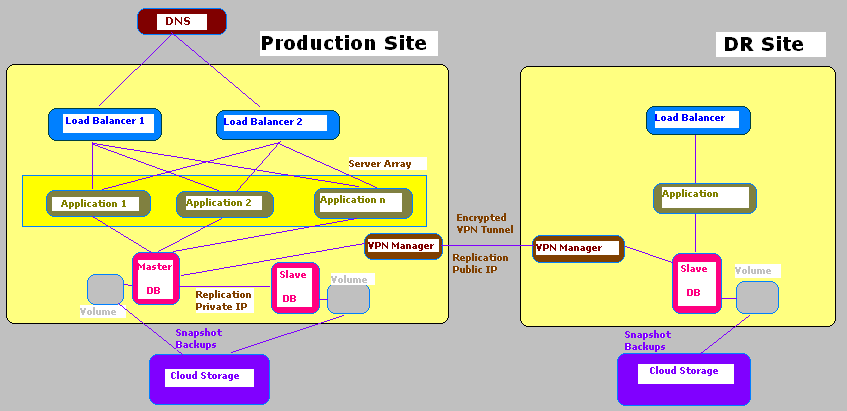
HIGH AVAILABILITY in more detail
In front of the Apache cluster we create a load balancer that splits up incoming requests between the two Apache nodes. Because we do not want the load balancer to become another "Single Point Of Failure", we provide high-availability for the load balancer, too. Therefore our load balancer will in fact consist out of two load balancer nodes that monitor each other using heartbeat, and if one load balancer fails, the other takes over silently, instantly.
The advantage of using a load balancer compared to using round robin DNS is that it takes care of the load on the web server nodes and tries to direct requests to the node with less load, and it also takes care of connections/sessions. If you application uses sessions, if a user is in a session on Apache node 1, he would lose that session if suddenly node 2 served the user's requests. In addition to that, if one of the Apache nodes goes down, the load balancer realizes that and directs all incoming requests to the remaining node which would not be possible with round robin DNS.
For this setup, we need four nodes (two Apache nodes and two load balancer nodes) and five IP addresses: one for each node and one virtual IP address that will be shared by the load balancer nodes and used for incoming HTTP requests.
As for the database high availability, database replication together with heartbeat will be utilized. For example in a standard MySQL Replication the master server writes updates to its binary log files and maintains an index of those files in order to keep track of the log rotation. The binary log files serve as a record of updates to be sent to slave servers. When a slave connects to its master, it determines the last position it has read in the logs on its last successful update. The slave then receives any updates which have taken place since that time. The slave subsequently blocks and waits for the master to notify it of new updates.
When you implement such a solution, you can write automated scripts that will backup your VM images and data and application backup automatically to a cloud storage.
Add Comment
This policy contains information about your privacy. By posting, you are declaring that you understand this policy:
- Your name, rating, website address, town, country, state and comment will be publicly displayed if entered.
- Aside from the data entered into these form fields, other stored data about your comment will include:
- Your IP address (not displayed)
- The time/date of your submission (displayed)
- Your email address will not be shared. It is collected for only two reasons:
- Administrative purposes, should a need to contact you arise.
- To inform you of new comments, should you subscribe to receive notifications.
- A cookie may be set on your computer. This is used to remember your inputs. It will expire by itself.
This policy is subject to change at any time and without notice.
These terms and conditions contain rules about posting comments. By submitting a comment, you are declaring that you agree with these rules:
- Although the administrator will attempt to moderate comments, it is impossible for every comment to have been moderated at any given time.
- You acknowledge that all comments express the views and opinions of the original author and not those of the administrator.
- You agree not to post any material which is knowingly false, obscene, hateful, threatening, harassing or invasive of a person's privacy.
- The administrator has the right to edit, move or remove any comment for any reason and without notice.
Failure to comply with these rules may result in being banned from submitting further comments.
These terms and conditions are subject to change at any time and without notice.
- Data Science
- Android
- React Native
- AJAX
- ASP.net
- C
- C++
- C#
- Cocoa
- Cloud Computing
- HTML5
- Java
- Javascript
- JSF
- JSP
- J2ME
- Java Beans
- EJB
- JDBC
- Linux
- Mac OS X
- iPhone
- MySQL
- Office 365
- Perl
- PHP
- Python
- Ruby
- VB.net
- Hibernate
- Struts
- SAP
- Trends
- Tech Reviews
- WebServices
- XML
- Certification
- Interview
categories
Related Tutorials
Power On a VM from ESXI command line
How to change the virtual machine name in Azure
Install OpenStack step by step guide
How to get the API key for CloudStack
HA and DR in a cloud environment such as Amazon EC2
Backup and recovery in a cloud environment such as Amazon EC2
Application Security in a cloud environment such as Amazon EC2
Comments